Early days, the mask optimization relies on the empirical rules which usually depend on the geometry of the layout patterns. The contours of the layout patterns are decomposed into the edges and corners and the positions of their end points are varied and optimized according to the rules subtracted from the experimental facts
[24]. Even though computationally efficient, the rule based optimization methods are not able to provide the required accuracy and fail to fulfill the requests of the advanced technological nodes. A more robust iterative optimization method based on the optical models, photoresist models et. al. is introduced. The basic idea is to change the positions of the end points of the edges and corners mentioned above and the simulated images on the wafer are obtained accordingly. The full optimization cycle is stopped once the target patterns and the simulated images match each other. Different kinds of error functions are applied to provide a quantitative estimation of the deviations between the target patterns and the simulated images. The Edge Displacement Error (EDE)
[25], Edge Placement Error (EPE)
[26] or Pixel-wise Error Summation
[27] et. al. are usually calculated. The optimization process is usually computationally expensive due to the slow convergence of the iterations. While coarser models which are more computationally tractable are applied at the cost of the accuracy, the effort of the reduction of the iterations inspired the early application of machine learning techniques to the OPC regime and it remains as a main purpose of machine learning based OPC packages till nowadays.
The earlier attempt to obtain a better initial guess for the mask optimization process with the linear regression methods done by the researchers at University of California, Berkeley becomes an excellent start point in this track
[28]. Taking advantage of the large dataset of the modified mask patterns after OPC by the commercial EDA packages, the authors estimate the expected fragment movement by the simplest linear statistical model provided an input target layout pattern. It provides a prototype of the basic ideas of the machine learning based OPC technologies within the framework of the supervised learning method. The realization of the workflow still requires the involvement of the advanced commercial EDA packages to generate the labeled data (the correct fragment movement given a specific mask pattern as the original input). As a result, the upper bond of the accuracy of this type of method is constrained by the correctness of the simulators and the efficiencies of the optimizers of the relevant commercial software. And the performance of such method is further compromised by the oversimplification of the mapping from the original input mask pattern to the predicted fragment movements by the application of a linear model.
However, the trained linear model serves as a coarse optimizer of the input mask pattern which provides the optimized mask pattern in a single run while it is fed by the input feature vectors representing the original mask patterns. The authors successfully reduce the number of iterations of the traditional OPC workflow by the replacement of the original mask pattern with the statistically learned one as the initial condition of the subsequent optimization flow.
Another significant contribution of the authors is that they successfully introduce a representation method for the input mask layout which makes the further calculation they complete computationally feasible. The discrete cosine transform (DCT) is applied to the input mask layout, and first hundreds of the DCT coefficients is collected in the Zig-Zag order (Shown in Figure 5.) as the input feature vectors of the linear model to be trained.
Figure 5.
Zig–zag ordering of DCT coefficients[28]. The feature engineering accomplished this way serves as one of the mainstream techniques in the OPC community before more efficient and universal feature learning techniques fitting the requirement of the end to end learning such as the prevalent convolutional neural network (CNN) techniques are introduced from the deep learning community. The DCT is also applied by other researchers in the OPC community later in different ways including the variant form of the Fourier Transforms
[29–32]. Even after the CNN et. al. deep learning techniques are introduced and the representation learning is realized automatically independent of the input data formulations, DCT is sometimes still used as the pre-processed data type as the neural network inputs
[33].
The trained models after the supervised learning as the optimizer instead of the traditional iterative optimization circle are further improved mainly in two aspects: more complicated and accurate model instead of the linear statistical model are used to approximate the mapping between the input mask pattern and the optimized mask pattern (the optimization can be in the form of either motions of the specific edge fragment or the modified mask patterns as a whole.); Different feature engineering can be done or the representation learning within the scope of the deep learning can be applied to the mask pattern and the dimensional reduction can be realized in varied ways accordingly
[34].
A direct improvement of the representation capability of the linear model has been done by Tetsuaki Matsunawa et. al.
[35] by the application of the generalized linear mixed model instead to include the edge type effect. Considering the universal approximation property of the multilayer neural network, replacing the linear model with the typical multilayer neural network becomes another natural choice and has been done by Rui Luo
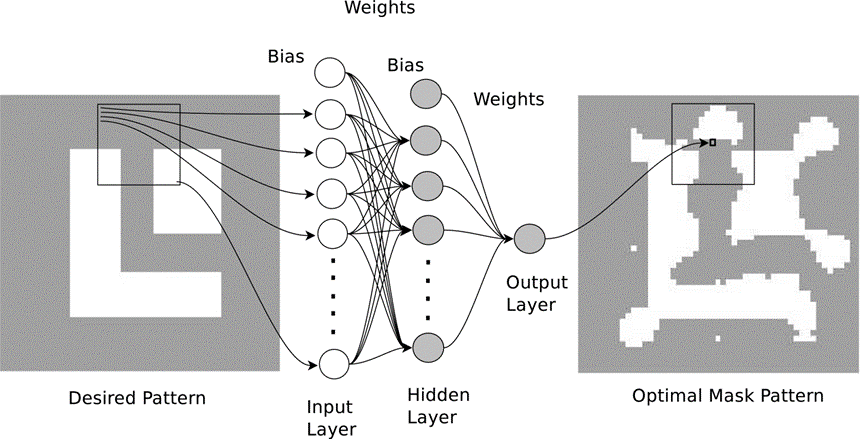
[36]. The author considering the estimation of the binary value of the central pixel of the square modified mask pattern by the standard three layer neural network with the original pixel level binary mask pattern as the input instead of estimating the motion of the central fragment. To obtain the whole modified mask pattern, the author has to scan the three layer model over the original mask pattern. The schematics of the NN is shown in Figure 6. Such kind of scanning can be done naturally by the introduction of the convolutional neural networks and the three layer neural network above can actually be treated as the convolutional layer.
Figure 6.
The schematics of the NN for OPC[36]. The contemporary convolutional neural networks (CNN) with varied architectures have been invented and widely applied to different scenes such as image segmentation, object recognition, image classification et. al.
[37]. Basically, it is critical that the actual input of the prevalent CNNs is usually the tensor type data instead of the flatten one used in the Rui’s work, and the convolution layer/Kernel layer with the shared weight parameters slides across the input tensor. The pooling layers are usually applied to further reduce the dimensions of the features learned. After the invention of the training methods of the deep neural networks such as the backpropagation et al.
[38], the CNNs emerges. The critical advantage of the deep CNNs is that they permit the representation learned from the multiple levels of the abstraction which are realized by the stacking of varied convolutional kernels and pooling layers. It avoids the necessity of the designing effort of feature engineering by human wisdom and enables the end to end training of models which can be widely applied. The CNNs are immediately fetched by the OPC community and relevant works have been done recently. Once we constrain our discussion within the mask pattern optimization or source optimization problems, the representation of the image patterns by the latent vectors and their decoding are naturally involved and can be directly linked to the encoder-decoder structures. For example, the convolutional autoencoder is trained to do the Source Mask Optimization by Ying Chen et. al.
[39] to dramatically raise the speed of the optimization process by a factor of 10
5. Their model output is shown in Figure 7.
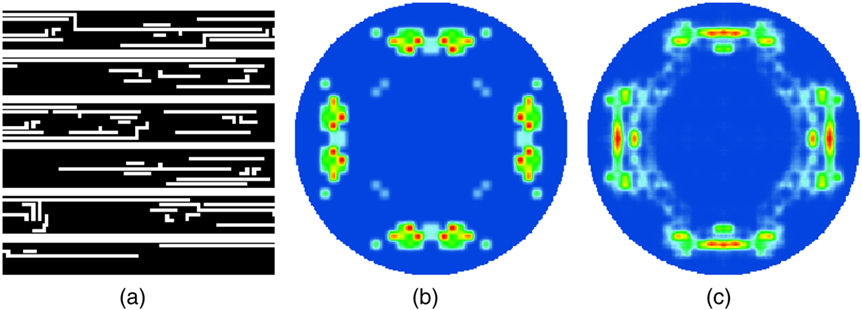
Figure 7.
Illustrations of (a) a layout clip, (b) a model-based source, and (c) an autoencoder-based source. [39] Similarly, the stacking convolutional architectures are also implemented by Haoyu Yang et al.
[40] to form the generator and discriminator of the generative adversarial network (GAN)
[41] when they succeed in realizing the mask optimization with the modified discriminator design. After the GAN converges, the generator can be used to calculate the optimized mask pattern of the original input one within 0.2s which is negligible compared with the traditional OPC methods. The convolutional autoencoders (CAE) are also applied in other regimes such as the insertion of the Sub Resolution Assist Features (SRAF) et. al.
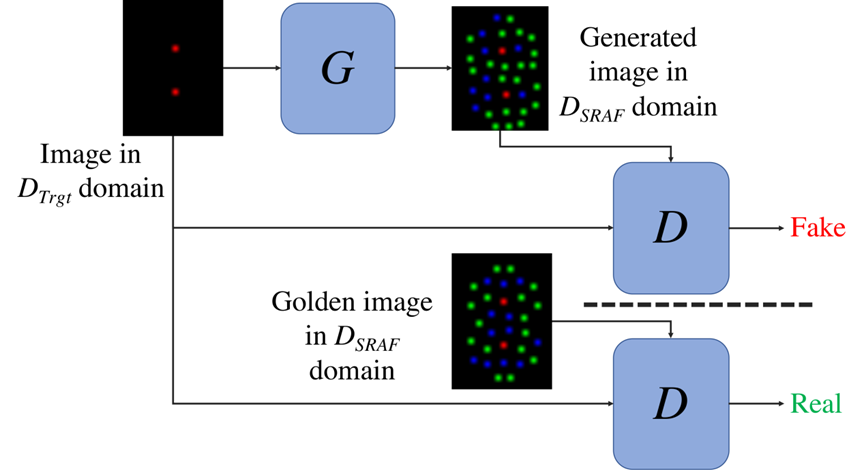
[42]. They can be trained as GAN shown in Figure 8.
Figure 8.
An overview of the CGAN functionality[42]. Basically transformed into a image generation or translation problem
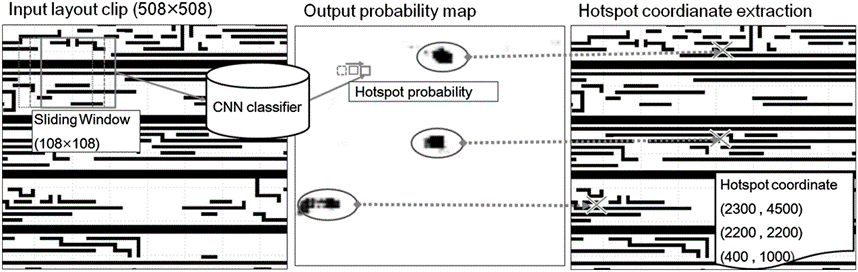
[43, 44], the graphic generation of the modified mask pattern can be done by the mainstream computer vision techniques. Proper modifications made to the design of the specific architectures are necessary. Autoencoders can serve as the models or function approximators of the mapping between the input mask pattern and optimized mask pattern. The training process or the learning of the relevant parameters are finished in the supervise learning mode. In fact, the trained models as the optimizers are not necessarily functioned as the generators of the optimized mask or source patterns. They can also be easily applied as the classifiers for other OPC purposes. We are trying to separate these applications into different categories of OPC techniques although mathematically they are the same in the sense that they eventually act as function approximators providing the appropriate mappings minimizing the designed loss functions. The output can be either mask patterns, source patterns or the labels. We will leave these discussion to the next section where the pattern selection and hotspots detection
et. al. are discussed.